On December 23, 2025, Prof. Wenjin Li’s team at the Institute for Advanced Study, Shenzhen University, published a research article in the Journal of Chemical Information and Modeling entitled “AttentionScore: A Target-Specific, Bias-Aware Scoring Function for Structure-Based Virtual Screening: A Case Study on METTL3.” The study proposes AttentionScore, a deep learning scoring function that is target-specific for METTL3 and explicitly bias-aware. Prof. Wenjin Li is the corresponding author, and postdoctoral researcher Muhammad Junaid is the first author.
Research background and challenges
Structure-based virtual screening (SBVS) relies heavily on scoring functions to discriminate protein–ligand binding. However, generic scoring functions often fail to capture target-specific interaction details. In addition, virtual screening datasets commonly suffer from issues such as artificial enrichment, analogue bias, and false negative bias, which can inflate benchmarking results and undermine real-world generalization.
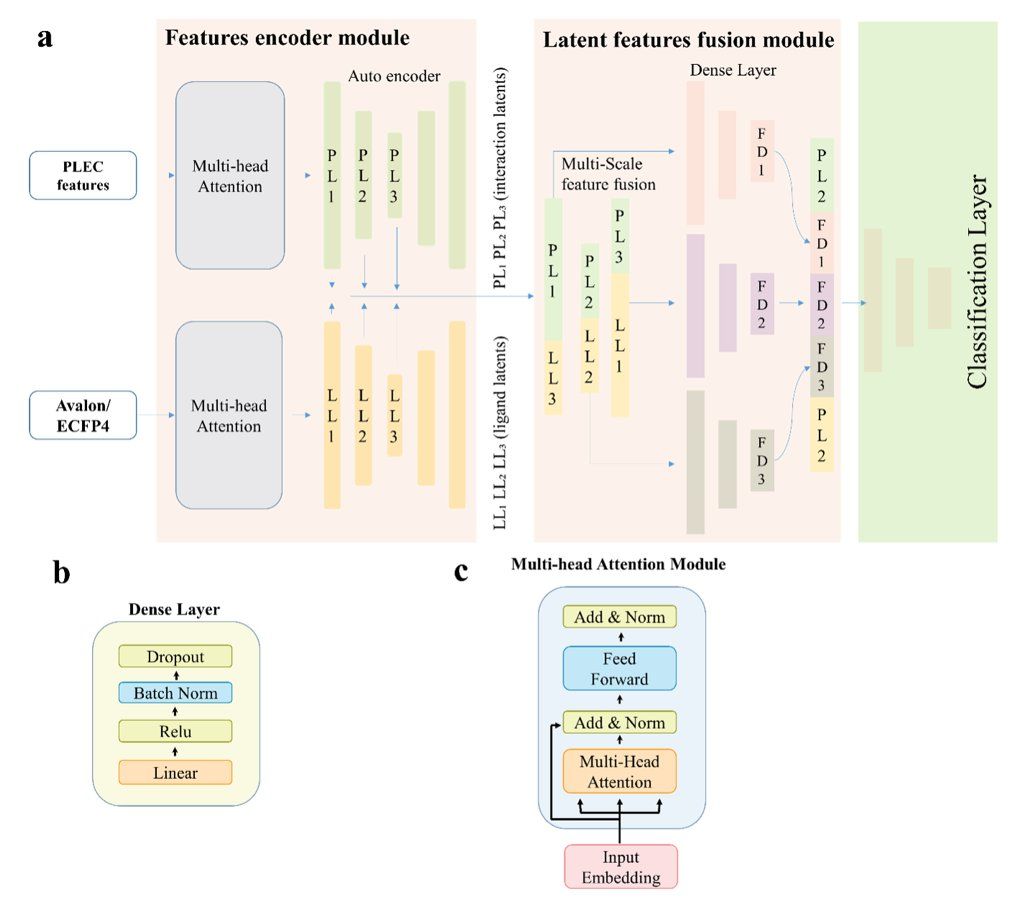
Figure 1. AttentionScore Framework: The ligand fingerprints and protein–ligand interaction fingerprints are separately input into parallel branches composed of multi-head attention encoders to extract hierarchical latent representations. These representations are fused at multiple scales and then further optimized by a fully connected layer, ultimately outputting classification scores for virtual screening.
Core contribution:
Methodological innovations in AttentionScore
The proposed AttentionScore is a deep learning scoring function tailored to METTL3, integrating ligand fingerprint information (Avalon/ECFP4) and protein–ligand interaction fingerprints (PLEC) within a unified end-to-end framework. The model includes three key design elements: a multi-head attention encoder to extract informative signals while suppressing redundancy; an autoencoder-style latent representation for compression and denoising to improve stability; a multiscale latent feature fusion module that cross-couples ligand and interaction information at different levels and preserves robust mid-level signals through skip connections, achieving a better balance between performance and generalization.
Bias-aware evaluation: testing true generalization with stricter splits
To reduce analogue leakage, the study designed an ECFP4-based similarity-constrained (SC) split, using Butina clustering with a Tanimoto threshold of τ = 0.50, and assigning train/test sets at the cluster level to prevent highly similar compounds from being distributed across sets. The authors further defined a more extrapolative Hard Test Set (Set 2), requiring each test compound to have a maximum similarity of no more than 0.50 to all training compounds. The team also systematically compared cross-set similarity matrices and leakage diagnostics across SC, scaffold, and random splits, demonstrating that the SC protocol substantially reduces near-duplicates and scaffold leakage, making evaluation closer to practical deployment scenarios.
Key results:
Strong performance under stringent conditions
On the SC test set (Set 1), AttentionScore (PLEC + Avalon) achieved PR-AUC = 0.9609, Precision = 0.9698, Recall = 0.7277, F1 = 0.8057, and MCC = 0.7388, and it maintained robust performance on the more challenging Set 2. In comparisons with multiple generic scoring functions (e.g., CNNScore, SCORCH, RFScore, and smina) and machine-learning baselines, AttentionScore showed superior performance on key metrics and improved stability. Paired Wilcoxon tests, bootstrap confidence intervals, and effect-size analyses further supported that these gains were not artifacts of dataset splitting.
Open-source and usability: a visual interface to lower the barrier to adoption
To facilitate use by non-specialists, the team provides a Streamlit-based graphical user interface, supporting end-to-end workflows such as “Docked SDF → prediction,” “MOL2 → docking → prediction,” and “SMILES → 3D building → docking → prediction.” The authors also release data, code, and pretrained models to enable reproducibility and extension to other targets for developing target-oriented scoring functions.
Funding
This work was supported by the Natural Science Foundation of Guangdong Province (Grant No. 2023A1515010471) and the Shenzhen Science and Technology Innovation Commission (Grant No. JCYJ20240813142512017).
Article link: https://pubs.acs.org/doi/10.1021/acs.jcim.5c02142?ref=pdf

